PostgreSQL High Availability
I’ve been researching PostgreSQL high availability solutions recently, and here’s what I’ve learned.
PostgreSQL High Availability
High Availability Goals
PostgreSQL high availability typically has two main objectives:
- RPO (Recovery Point Objective): The maximum acceptable amount of data loss measured in time. This represents how much data loss a business can tolerate.
- RTO (Recovery Time Objective): The maximum acceptable downtime, measured from when a disaster occurs until the system is operational again. This represents how quickly the system needs to be restored. In simple terms, this means determining how quickly to restore the database and to what state - for example, recovering within 5 minutes to a state no more than 30 minutes old. The ideal scenario would be RTO < 30s and RPO ≈ 0.
Scenarios
To achieve the ideal scenario mentioned above, the following situations need to be addressed:
- When the Primary node fails, automatic failover to the Standby node occurs within RTO requirements while meeting RPO goals.
- When accidental data deletion occurs, upgrade errors happen, or hardware failures occur, the ability to recover to a specific point in time.
Concepts
To handle these scenarios, the following technologies and concepts are essential:
- Continuous Archiving: Generally involves archiving WAL (Write Ahead Log) files; in case of database system crashes, recovery can be performed by replaying WAL.
- Point-in-Time Recovery (PITR): For hardware failures, high availability failover based on physical replication might be the best choice. For data corruption (whether machine or human error), Point-in-Time Recovery (PITR) is more appropriate as it provides a safety net for worst-case scenarios.
- Physical Replication: Complete replication of data files and transaction log files (PGData, pg_wals)
- Logical Replication: Replication between publisher and subscriber based on replication identifiers (e.g., primary keys), typically used for Foreign Data Wrapper (FDW) scenarios rather than disaster recovery.
- Streaming Replication: WAL log-based streaming replication, primarily used for disaster recovery. WAL XLOG records are continuously transmitted from primary to standby, available in both synchronous and asynchronous modes.
Tools
Backup and Restore
Here are the common backup and recovery methods along with their pros and cons:
1. Pg_dump (Logical Backup)
Logical backup exports database data to a file using the pg_dump SQL command, which can then be imported back using SQL commands.
Advantages:
- Logical backups can be performed at table to database level as needed
- Backups don’t block read/write activities on the database
- Can be restored to different major PostgreSQL versions and even different operating system architectures Disadvantages:
- Logical backups require replay during recovery, which can take considerable time for large datasets and may impact overall performance
- Doesn’t support dumping global variables, requires pg_dumpall instead
2. Physical Backup
Physical backup is an offline backup of the PostgreSQL cluster performed when the cluster is stopped, containing the entire cluster data. Advantages:
- Fast backup and recovery
- Suitable for large databases
- Ideal for high availability scenarios Disadvantages:
- Cannot restore across different versions
- Cannot restore across different operating systems
3. Continuous Archiving and Point-in-Time Recovery (PITR)
Online Backup or Hot Backup starts with a full backup that can be performed online without stopping the PostgreSQL cluster. Incremental backups generate WAL logs, which can then be used for recovery through WAL archive replay. Advantages:
- Can recover to any point in time
- No application downtime required Disadvantages:
- May require significant time to recover data from archives, primarily used for massive databases that cannot be backed up frequently
4. Snapshots and Cloud Backups
Snapshots require operating system or cloud provider support, with tools like rsync available for taking snapshots. Disadvantages:
- Not suitable when database tablespaces are stored across multiple drive volumes
Several considerations go into backup planning, including frequency, storage location, recovery time, and retention policies. Here are some popular open-source tools to assist with backups:
- pgbackrest
- EDB barman
- WAL-G From this discussion, barman lacks some features compared to pgbackrest:
- Zstd compression
- Delta restore
- Encryption at rest
- Native postgres page checksum validation
- Multi repo
High Availability
Patroni uses asynchronous Streaming Replication by default, meaning transactions committed on the primary node may take some time to replicate to standby nodes. During this time, if the primary node fails, data from this period could be lost. Synchronous replication can be used to reduce data loss, but this affects primary node performance as it must wait for all standby nodes to receive and write WAL logs before committing transactions. A balance between availability and performance must be struck.
Patroni’s maximum_lag_on_failover and PostgreSQL’s wal_segsize need to be balanced between availability and durability:
maximum_lag_on_failoverdefaults to 1MB (1048576 bytes), meaning if a node lags beyond this value, it won’t be chosen as the new primary. This typically works in conjunction withloop_waitandttlparameters. For example, with a ttl of 30, if a Patroni node fails to renew with Etcd or Consul within 30 seconds, it loses leadership. With loop_wait set to 10 seconds, Patroni performs its main operation loop every 10 seconds, including status checks and necessary operations. Worst-case data loss: maximum_lag_on_failover bytes + logs written in the last TTL seconds. Reducing this value lowers the upper limit of data loss during failover but increases the chance of automatic failover being rejected due to unhealthy replicas (too far behind).wal_segsizeparameter defines the size of each WAL log segment file, defaulting to 16MB
Architecture
There are many PostgreSQL high availability architectures available. Here are two common architectures, corresponding to self-hosted PostgreSQL and cloud-hosted PostgreSQL typical architectures:
Pigsty HA Architecture
The following diagram is from pigsty:
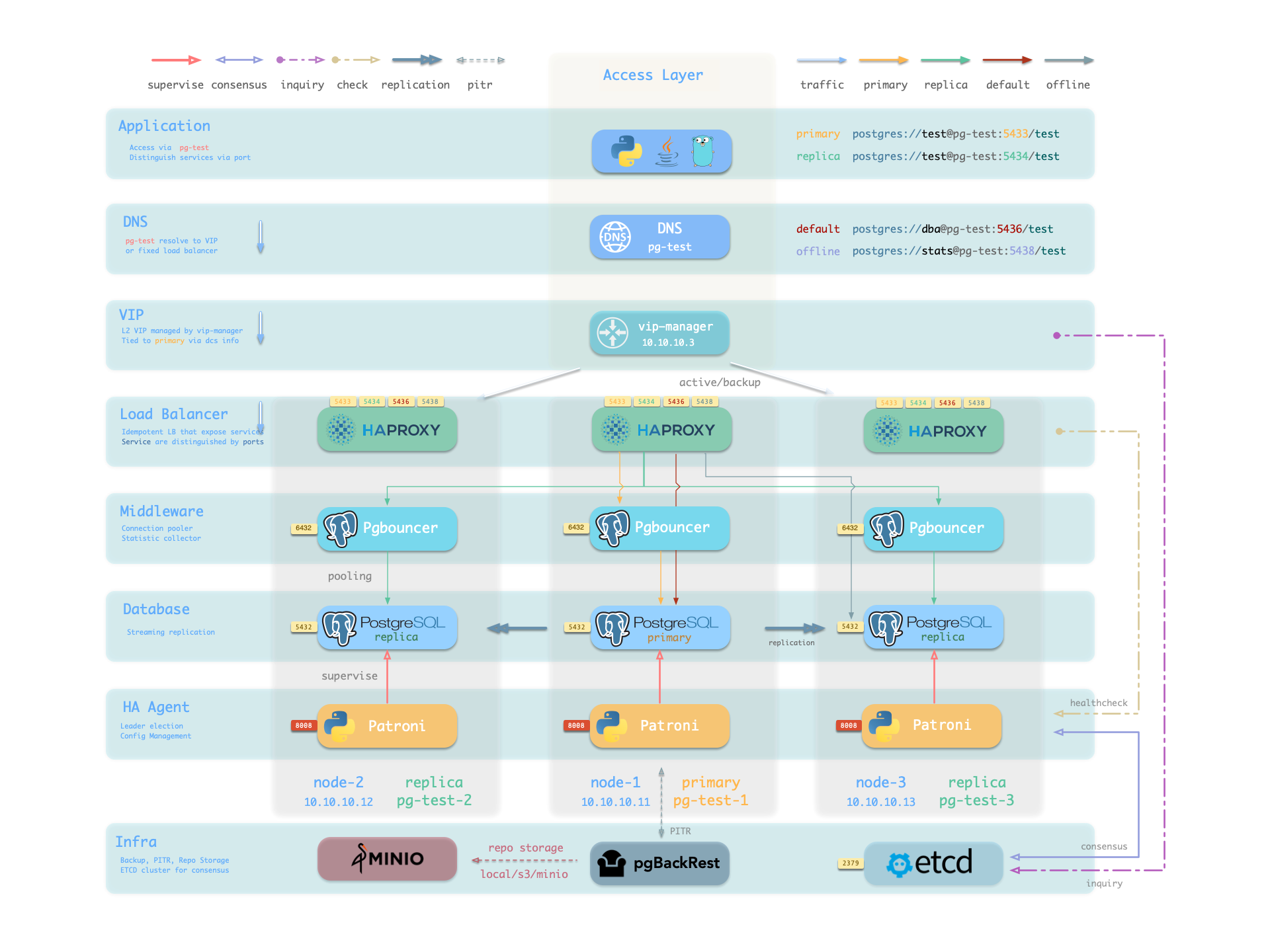
From top to bottom:
- Application layer resolves DNS to vip-manager’s VIP, vip-manager gets the current primary’s IP address through etcd, then binds the L2 VIP to the primary node; HAProxy handles L5 layer port forwarding.
- Patroni: Synchronizes primary node information to etcd.
- vip-manager: Virtual IP and state managed synchronously by etcd.
- HAProxy: Routes based on ports
- 5433: Connects to PGBouncer pool for primary read/write
- 5434: Connects to PGBouncer pool for replica read-only
- 5436: Direct connection to primary for management
- 5438: Direct connection to replica for management, connects to dedicated replicas not handling online read traffic, used for ETL and analytical queries.
- Primary and replica synchronize WAL logs through Streaming Replication, primary sends WAL logs to replica via pg_receivexlog, replica replays WAL logs via pg_replay.
- Patroni performs backups through pgBackRest, backup data can be stored locally, in remote s3 or minio storage, refer to the documentation.
- PostgreSQL uses standard streaming replication to set up physical replicas, with replicas taking over when the primary fails.
- Patroni manages PostgreSQL server processes and handles high availability matters.
- Etcd provides distributed configuration storage (DCS) capability and is used for leader election after failures
- Patroni relies on Etcd to reach cluster leader consensus and provides health check interfaces.
- HAProxy exposes cluster services and automatically distributes traffic to healthy nodes using Patroni health check interfaces.
- vip-manager provides an optional layer 2 VIP, gets leader information from Etcd, and binds the VIP to the node hosting the cluster’s primary. With primary-replica architecture + automatic failover + synchronous streaming replication + pgBackRest backup, RTO is within 1 minute and RPO is 0, meaning recovery within 1 minute with no data loss.
Cloudnative-PG HA Architecture
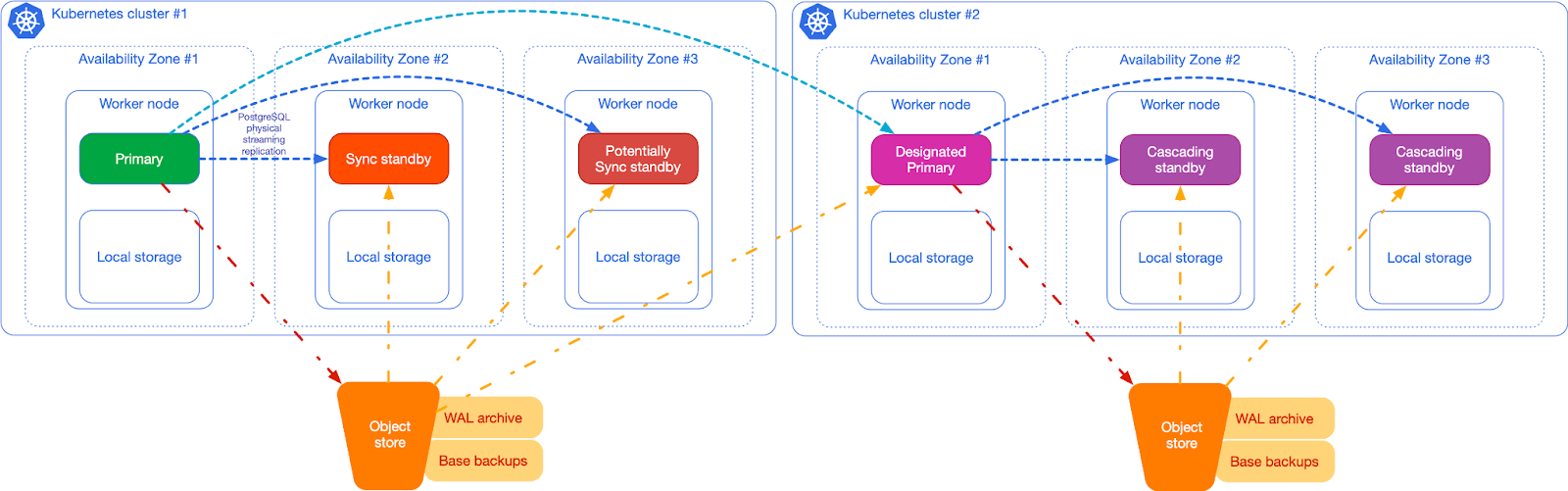
Based on Kubernetes container orchestration characteristics, Cloudnative-PG HA architecture adopts a more modern approach:
- Multi-region Kubernetes deployment
- PostgreSQL nodes deployed across multiple availability zones (three or more)
- Primary-Standby using synchronous or asynchronous Streaming Replication
- PostgreSQL instances don’t share resources, have dedicated node resources, run on different Kubernetes worker nodes, use local volumes
- Application layer provides
rw,ro,rservices for connecting to primary node, hot standby replicas for read-only workloads, and any read-only workloads respectively; during failover, it automatically updates services to point to the promoted service, ensuring seamless traffic redirection from applications. - Provides Pooler object to create PGBouncer connection pools for connecting to primary and read-only nodes
- Deploys PostgreSQL across multiple Kubernetes clusters through Replica Cluster
- Reduces global Recovery Point Objective (RPO) by storing PostgreSQL backup data across multiple locations, regions, and potentially different providers (disaster recovery)
- Reduces global Recovery Time Objective (RTO) by leveraging PostgreSQL replication outside the primary Kubernetes cluster (high availability)
- Designated primary cluster can be promoted at any time, making the replica cluster the primary cluster accepting write connections.
- WAL archiving through s3
- Backups through barman, can backup to cloud object storage like s3 or use Volume Snapshot
Under this architecture, cross-region disaster recovery provides approximately 5 minutes RPO at most, with synchronous Streaming Replication achieving 0 RPO and extremely low RTO.
Supabase Backup
Click me
```mermaid
graph TD;
A(Supabase Backup)--->B(Pro);
B(Pro)--->E(Database Size 0-40GB);
B(Pro)--->F(Database Size 40GB+);
B(Pro)--->G(PITR);
B(Pro)--->H(Read Replica);
E(Database Size 0-40GB)--->I(Logical Backup);
F(Database Size 40GB+)--->J(Physical Backup);
G(PITR)--->J(Physical Backup);
H(Read Replica)--->J(Physical Backup);
A(Supabase Backup)--->C(Team);
C(Team)--->K(Database Size 0-40GB);
C(Team)--->L(Database Size 40GB+);
C(Team)--->M(PITR);
C(Team)--->N(Read Replica);
K(Database Size 0-40GB)--->I(Logical Backup);
L(Database Size 40GB+)--->J(Physical Backup);
M(PITR)--->J(Physical Backup);
N(Read Replica)--->J(Physical Backup);
A(Supabase Backup)--->D(Enterprise);
D(Enterprise)--->O(Database Size 0-40GB);
D(Enterprise)--->P(Database Size 40GB+);
D(Enterprise)--->Q(PITR);
D(Enterprise)--->R(Read Replica);
O(Database Size 0-40GB)--->J(Physical Backup);
P(Database Size 40GB+)--->J(Physical Backup);
Q(PITR)--->J(Physical Backup);
R(Read Replica)--->J(Physical Backup);
```

Click me
```mermaid
graph TD;
A(Supabase Backup)-->B(Pro);
A(Supabase Backup)-->C(Team);
A(Supabase Backup)-->D(Enterprise);
B(Pro)-->E(Daily Backup, Retain 7 days);
E-->H(pg_dumpall logical backup, when database size > 40GB will use physical backup);
C(Team)-->F(Daily Backup, Retain 2 weeks);
F-->H(pg_dumpall logical backup, when database size > 40GB will use physical backup);
D(Enterprise)-->G(Daily Backup, Retain 1 month);
D-->J(physical backup);
```

Users can access the daily generated logical backup SQL files for restore.
Click me
```mermaid
graph LR;
A(Supabase PITR)-->B(WAL-G, archiving Write Ahead Log files, default 2 min or certain file size threshold and physical backups);
B-->C(2 minutes RPO);
C-->D(show database restore available from and latest restore available at);
```

Click me
```mermaid
graph LR;
A(PGVecto.rs Cloud PITR)-->B(barman-cloud-wal-archive archiving Write Ahead Log files, default 5 min or certain file size threshold and barman-cloud-backup for physical backups);
B-->C(5 minutes RPO);
C-->D(show database restore available from and latest restore available at);
D-->E(delete cluster will delete all wal and physical backups);
```
