OpenClaw 为什么总失忆?一套从单会话到永久记忆的 Memory 方案
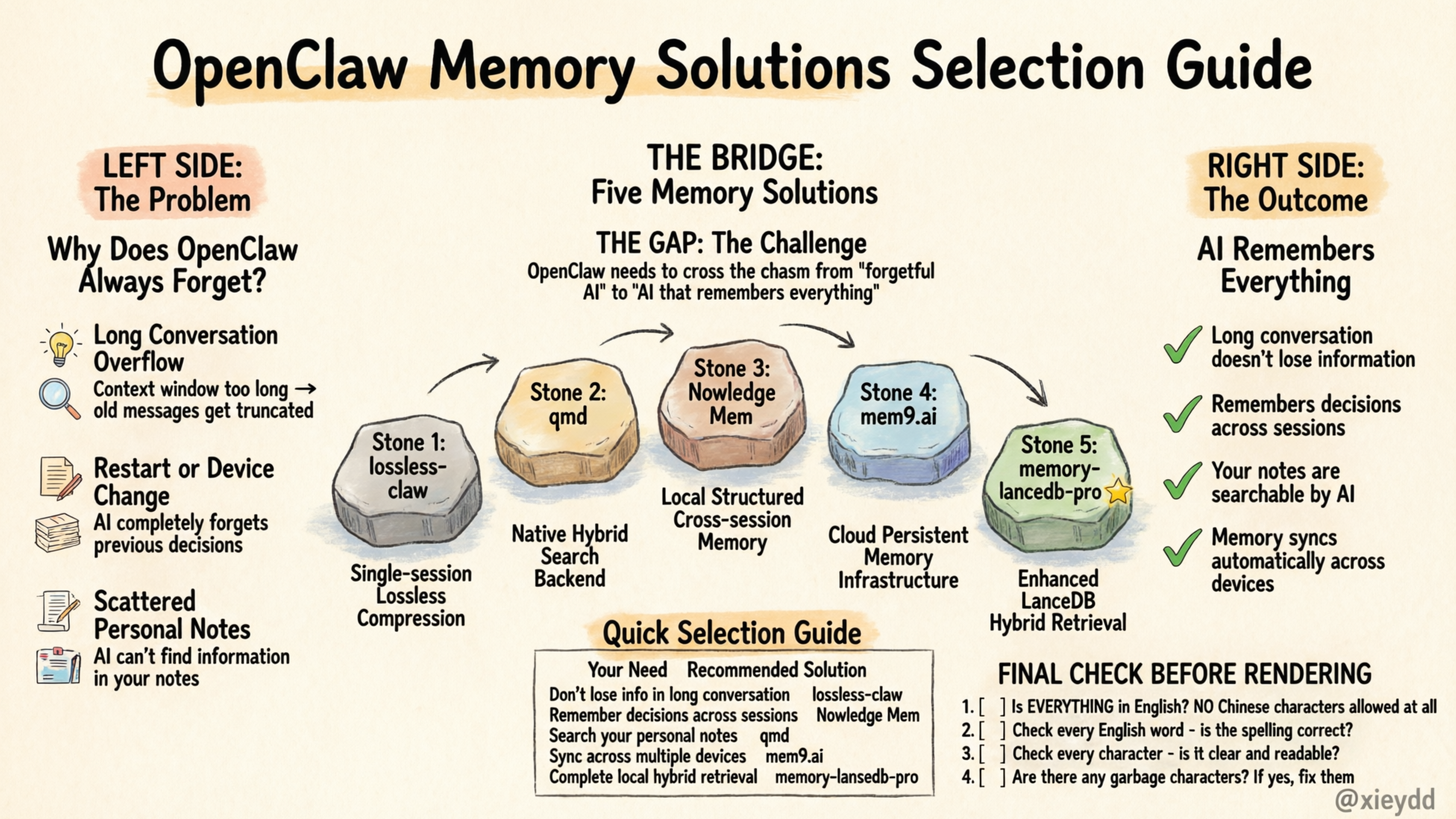
你是否有过这种经历?和 OpenClaw 聊了几个小时,上下文超限后旧消息被截断,下次重启会话 AI 直接忘了之前做过什么决定;散落各处的技术笔记想找找不到;多设备切换后记忆全没了。
OpenClaw 作为一个灵活的 Agent 框架,生态里已经发展出了多种记忆方案,各自解决不同问题。本文帮你理清脉络,一分钟选到适合自己的。
记忆到底要解决什么问题?
我们先把需求拆解开,AI 记忆其实分两个完全不同的维度:
| 维度 | 问题 | 解决思路 |
|---|---|---|
| 单会话内记忆 | 对话太长超出模型上下文窗口,直接截断会丢信息 | 压缩旧消息,保持上下文在窗口内,但尽量不丢失信息 |
| 跨会话记忆 | 重启会话、换设备后,AI 完全忘了之前聊过什么、做过什么决定 | 持久化存储历史,需要时自动召回相关内容 |
| 外部知识库 | 个人笔记、技术文档需要能被 AI 搜索到,融入对话 | 建立文档索引,支持混合搜索召回 |
不同方案侧重不同,我们一个一个说,附带详细配置步骤。
方案一:lossless-claw —— 单会话无损压缩
项目地址:https://github.com/Martian-Engineering/lossless-claw
一句话定位:替换 OpenClaw 原生滑动窗口截断,DAG 分层压缩,什么原始信息都不丢。
核心特点
- LCM(Lossless Context Management)算法:旧消息不是直接删除,而是分层压缩成摘要,形成有向无环图(DAG)
- 原始永远保留:所有原始消息存在 SQLite,Agent 需要时可以用
lcm_grep/lcm_expand搜索展开找回细节 - 开箱即用:安装后替换
contextEngine插槽,自动工作,用户不用管
安装配置步骤
|
|
安装命令会自动配置插槽,如果你需要手动配置,编辑 ~/.openclaw/openclaw.json:
|
|
推荐配置(环境变量方式):
|
|
| 参数 | 推荐值 | 说明 |
|---|---|---|
LCM_FRESH_TAIL_COUNT |
32 | 最近 N 条消息不压缩,保留原始内容 |
LCM_INCREMENTAL_MAX_DEPTH |
-1 | -1 表示无限制深度分层压缩 |
LCM_CONTEXT_THRESHOLD |
0.75 | 占用 75% 上下文窗口触发压缩 |
重启 OpenClaw 生效。验证:
|
|
适合你,如果:
- ✅ 你经常有长对话,希望超出上下文窗口也不丢原始信息
- ✅ 你只需要单会话内压缩,跨会话重置依赖 OpenClaw 原生机制
- ✅ 纯本地,不需要额外服务
方案二:qmd —— OpenClaw 原生混合搜索记忆后端
项目地址:https://github.com/tobi/qmd
官方文档:https://docs.openclaw.ai/concepts/memory#qmd-backend-experimental
一句话定位:OpenClaw 原生集成的本地混合搜索后端,替换内置 SQLite 索引器,提供 BM25+向量+重排序的三重混合搜索。
核心特点
- 原生集成:作为 OpenClaw memory backend 直接集成,无需单独配置 MCP
- 全栈本地:三个 GGUF 模型(嵌入+重排序+查询扩展)本地跑,不需要云服务
- 三重混合搜索:BM25 关键词 + 向量语义 + LLM 重排序,比单一搜索准确很多
- 自动降级:qmd 故障时自动降级到内置 SQLite 索引器,保证记忆工具始终可用
前置要求
|
|
安装 qmd
|
|
在 OpenClaw 中配置
编辑 ~/.openclaw/openclaw.json,添加以下配置:
|
|
配置说明:
| 参数 | 推荐值 | 说明 |
|---|---|---|
backend |
"qmd" |
启用 qmd 作为记忆后端 |
citations |
"auto" |
自动在搜索结果中添加来源标注 |
includeDefaultMemory |
true |
自动索引 MEMORY.md 和 memory/**/*.md |
update.interval |
"5m" |
每 5 分钟更新一次索引 |
limits.maxResults |
6 | 最多返回 6 条搜索结果 |
paths[] |
自定义 | 额外的 Markdown 笔记目录 |
验证配置
|
|
手动预下载模型(可选)
第一次搜索时 qmd 会自动下载模型,也可以手动预下载:
|
|
中文用户推荐配置
|
|
改完后需要重新生成索引:
|
|
适合你,如果:
- ✅ 你需要 OpenClaw 原生集成记忆搜索,不是外部 MCP 服务
- ✅ 有大量个人 Markdown 笔记/技术文档,希望 AI 能搜索引用
- ✅ 偏爱纯本地方案,不依赖云服务
- ✅ 需要混合搜索(关键词+语义+重排序),比单一向量搜索更准确
方案三:Nowledge Mem —— 本地优先结构化跨会话记忆
官网:https://mem.nowledge.co/zh/docs/integrations/openclaw
一句话定位:本地优先的结构化知识记忆,让 AI 记住你做过的决定、偏好,跨会话自动召回。
核心特点
- 结构化记忆:每条记忆标记类型(事实/决策/偏好/计划/…)、时间、来源关联,不是纯文本堆在一起
- 知识演化:认知变化了新增版本保留历史,能看到想法怎么演变的
- 全自动:
autoRecall会话开始自动插相关记忆,autoCapture会话结束自动保存提取 - 本地优先:默认存在本地,不需要云账户,隐私完全可控
- 跨工具共享:Cursor/Claude/OpenClaw 共享同一个记忆库,知识不属于某个工具
安装配置步骤
1. 安装 Nowledge Mem 并启动
Follow the official instructions: https://mem.nowledge.co/zh/docs/install 完成 nmem CLI 安装。
验证:
|
|
2. 安装 OpenClaw 插件
|
|
3. 配置 OpenClaw
编辑 ~/.openclaw/openclaw.json,替换 memory slot:
|
|
配置说明:
| 参数 | 推荐值 | 说明 |
|---|---|---|
autoRecall |
true |
会话开始自动召回相关记忆插入上下文 |
autoCapture |
false |
会话结束自动保存。false 表示只在你用 /remember 时保存,推荐新手从这个开始 |
maxRecallResults |
5-12 | 召回多少条结果放进上下文 |
4. 重启 OpenClaw 验证
|
|
适合你,如果:
- ✅ 你最痛的问题是"AI 下次会话就忘了我做过什么决定"
- ✅ 希望 AI 能记住你的偏好、决策、事实,新会话自动带上背景
- ✅ 偏爱本地优先,不想强制云端同步
- ✅ 需要结构化知识,不是简单存文本块
方案四:mem9.ai —— 云端持久化记忆基础设施
官网:https://mem9.ai/
一句话定位:云端托管的持久化记忆基础设施,给你的 Agent 提供跨设备跨会话云存储。
核心特点
- 零运维:开箱即用,不需要自己搭服务,秒级创建持久化后端
- 渐进式混合搜索:从纯关键词开始,加嵌入自动升级混合搜索,不需要重建索引
- 跨 Agent 共享:多个 Agent 共享记忆,云端同步一致
- 开源自托管:Apache 2.0,不想用官方云可以自己搭
安装配置步骤
Follow the official instructions: https://mem9.ai/SKILL.md
快速步骤:
- 在 https://mem9.ai 注册账号获取 API key
- 在 OpenClaw 中安装插件:
|
|
- 配置 API key 到环境变量或 OpenClaw 配置,重启生效。
适合你,如果:
- ✅ 你在多设备上用 OpenClaw,需要记忆跟着你走
- ✅ 不想折腾基础设施,希望云端帮你管好
- ✅ 需要多个 Agent 共享记忆
- ✅ 接受云存储,信任服务商的安全方案
方案五:memory-lancedb-pro —— 增强型 LanceDB 混合检索记忆层
项目地址:https://github.com/CortexReach/memory-lancedb-pro
一句话定位:OpenClaw 生态里功能最完整的 LanceDB 记忆方案,在嵌入式本地架构基础上,提供向量+BM25 混合检索 + 跨编码器重排序 + 多 Scope 隔离 + 管理 CLI全套能力。
核心特点
比 OpenClaw 内置的基础 memory-lancedb 增强了很多高级特性:
| 功能 | 内置 memory-lancedb |
memory-lancedb-pro |
|---|---|---|
| 向量搜索 | ✅ | ✅ |
| BM25 全文检索 | ❌ | ✅ |
| 混合融合(Vector + BM25) | ❌ | ✅ |
| 跨编码器重排序 | ❌ | ✅ |
| 时效性加成 / 时间衰减 | ❌ | ✅ |
| MMR 多样性去重 | ❌ | ✅ |
| 多 Scope 访问隔离 | ❌ | ✅ |
| 检索结果噪声过滤 | ❌ | ✅ |
| 自适应检索 | ❌ | ✅ |
| 完整管理 CLI | ❌ | ✅ |
| 任意 OpenAI 兼容 Embedding | 有限 | ✅(OpenAI/Gemini/Jina/Ollama 等) |
- 嵌入式零服务:完全本地运行,不需要独立数据库进程,零运维开箱即用
- 完整检索管线:向量 → BM25 → RRF 融合 → 重排序 → 时效加权 → 噪声过滤 → 多样性去重,全链路优化
- 原生 JS/TS 生态:对 OpenClaw 生态天然对齐,不需要额外抽象层适配
- 原生多模态支持:不仅文本记忆,还支持存储检索图片、音频、视频,未来扩展方便
- 增量写入友好:Lance 格式天生支持增量追加,完美匹配 Agent 每个会话写入新记忆的模式
安装
稳定版:
|
|
Beta 版(含最新特性):
|
|
配置推荐
完整配置示例(点击展开):
完整配置 JSON
|
|
中文用户推荐起步配置(已经调优):
|
|
重启生效:
|
|
适合你,如果:
- ✅ 你想要完整端到端的记忆检索体验,开箱即用
- ✅ 偏好纯本地嵌入式架构,不想运行独立数据库服务
- ✅ 需要向量+BM25混合搜索,比单一搜索准确率更高
- ✅ 需要高级特性如自动捕获、多 scope 隔离、噪声过滤
方案六:OpenViking —— 火山引擎开源上下文数据库,文件系统范式记忆管理
项目地址:https://github.com/volcengine/OpenViking
OpenClaw 插件:https://github.com/volcengine/OpenViking/tree/main/examples/openclaw-memory-plugin
一句话定位:专为 AI Agent 设计的开源上下文数据库,创新地采用文件系统范式统一组织记忆,官方提供 OpenClaw 记忆插件,实测任务完成率提升 49%,Token 成本降低 91%。
核心特点
OpenViking 解决了传统 RAG/记忆方案的五大痛点:
| 痛点 | OpenViking 解决方案 |
|---|---|
| 上下文碎片化 | 文件系统管理范式:记忆、资源、技能统一按 viking:// URI 组织,像操作本地文件一样管理记忆 |
| Token 消耗过高 | 分层上下文加载:L0 摘要/L1 概览/L2 详情,只在需要时加载详情,大幅降低 Token 消耗 |
| 检索效果差 | 目录递归检索:先定位目录再深度探索,比单一扁平向量搜索更精准 |
| 黑盒不可调试 | 可视化检索轨迹:完整保留目录浏览和检索路径,问题根源一目了然 |
| 记忆无法迭代 | 自动会话管理:会话结束自动提取长期记忆,让 Agent 越用越聪明 |
官方 Benchmark 结果
基于 LoCoMo10 长程对话测试集:
| 实验组 | 任务完成率 | 总输入 Token 成本 |
|---|---|---|
| OpenClaw 原生记忆 | 35.65% | 24,611,530 |
| OpenClaw + LanceDB | 44.55% | 51,574,530 |
| OpenClaw + OpenViking | 52.08% | 4,264,396 |
结论:相比原生 OpenClaw,OpenViking 任务完成率提升 46%,Token 成本降低 83%;相比 LanceDB,效果提升 17%,Token 成本降低 92%。
安装配置步骤
OpenViking 提供一键安装脚本,自动检测环境并配置:
|
|
脚本会自动:
- 检查环境依赖(OpenClaw、Python)
- 创建
~/.openviking/ov.conf配置文件 - 部署插件到 OpenClaw 扩展目录
- 自动配置 OpenClaw 启用 OpenViking 记忆
支持本地模式(插件自启动 OpenViking 服务)和远程模式(连接已部署的独立 OpenViking 服务)。
手动配置(本地模式)
|
|
配置 OpenClaw(编辑 ~/.openclaw/openclaw.json):
|
|
ov.conf 配置示例(使用火山引擎豆包模型):
|
|
启动验证:
|
|
手动配置(远程模式)
如果已经独立部署了 OpenViking 服务,只需要配置:
|
|
适合你,如果:
- ✅ 你追求更高的任务完成率和更低的 Token 成本,官方测试效果显著优于原生方案
- ✅ 你认同文件系统范式管理记忆的设计哲学,需要可调试、可观察的检索路径
- ✅ 你需要分层记忆,自动摘要+按需加载,控制上下文大小
- ✅ 支持本地/远程两种部署模式,个人开发者和团队都能用
一分钟选型对照表
| 你的需求 | 推荐方案 | 备注 |
|---|---|---|
| 长对话单会话内不丢信息 | lossless-claw | 必须装,解决上下文超限问题 |
| 跨会话记住决定/偏好 | Nowledge Mem | 本地优先,结构化,推荐大多数个人用户 |
| 追求最高检索效果 + 最低 Token 成本 | OpenViking | 火山引擎开源,官方测试效果提升 46%,成本降 83% |
| 多设备同步 + 零运维 | mem9.ai | 云端托管,方便 |
| 搜索个人 Markdown 笔记/文档 | qmd | OpenClaw 原生集成,GGUF 模型本地运行 |
| 嵌入式本地向量搜索,零额外服务 | LanceDB | 纯 JS 嵌入式,不需要独立数据库进程 |
| 全都想要 | 全部装 | lossless (单会话压缩) + OpenViking/Nowledge/qmd/LanceDB (跨会话/文档) 不冲突,配合使用效果最佳 |
推荐组合方案
个人开发者/重度笔记用户(完全本地):
|
|
这是最简洁的本地全栈方案,数据全在你自己机器上。可根据偏好选择:
- qmd: 全栈本地,三个 GGUF 模型完成混合搜索,不需要远程 API
- LanceDB: 嵌入式库零进程,依赖远程嵌入 API,资源占用更低
配置检查清单:
-
plugins.slots.contextEngine = lossless-claw -
agents.defaults.memory.backend = "qmd"或"lancedb" - 根据后端配置对应参数(qmd.paths 或 lancedb.uri)
需要跨会话记忆的用户:
根据你的基础设施偏好选择:
方案 A:OpenViking(推荐追求高性能)
|
|
配置检查清单:
-
plugins.slots.contextEngine = lossless-claw -
plugins.slots.memory = memory-openviking -
~/.openviking/ov.conf配置正确的 API Key
方案 B:Nowledge Mem(本地优先结构化)
|
|
配置检查清单:
-
plugins.slots.contextEngine = lossless-claw -
plugins.slots.memory = openclaw-nowledge-mem -
agents.defaults.memory.backend = "qmd"或"lancedb"
多设备流动用户:
|
|
方便,打开哪个设备都能接着聊。
验证配置正确
安装完所有组件后,可以跑一遍这个检查清单:
- lossless-claw: 开始一个长对话,聊到触发压缩,问 AI 能不能回忆起开头说的什么,如果能通过
lcm_expand找回,说明 OK - Nowledge Mem:
/remember存一条,/new开新会话,问能不能 recall 起来 - qmd: 让 AI “搜索我的笔记中关于 XXX 的内容”,看能不能返回正确结果
全部通过,你的 OpenClaw 现在就是一个"过目不忘"的 AI 助手了 🎉
后续:期待 PostgreSQL Native Memory Backend
如果你像我一样是 PostgreSQL 的重度用户,这里有个值得期待的功能:OpenClaw 社区正在讨论原生 PostgreSQL + pgvector memory backend(Issue #15093)。
为什么值得期待?
当前 qmd 方案虽然强大,但也有痛点:
- QMD 依赖 Bun + GGUF 模型,资源占用较高
- subprocess → CLI → SQLite → GGUF 模型的链路过长,故障点较多
- VPS/容器环境下本地模型性能不佳
PostgreSQL native backend 的优势:
- ✅ 零依赖:直接用
pg包连接数据库,无需 subprocess - ✅ 复用现有基础设施:很多用户已经运行 PostgreSQL,无需额外部署
- ✅ 生产级可靠性:pgvector 经过大规模验证
- ✅ 多实例共享:多个 OpenClaw 实例可以共享同一个记忆数据库
- ✅ 混合搜索:pgvector + tsvector 实现 BM25+ 向量双重检索
- ✅ 调试友好:直接用
psql检查状态,无需解析 SQLite - ✅ 海量向量支持:通过 VectorChord 无缝承接千万级向量,IVF+RaBitQ 架构实现低成本亿级检索
- ✅ 高性能全文检索:使用 VectorChord-bm25 替代原生 tsvector,Block-WeakAnd 算法显著提升 BM25 排名查询性能
- ✅ 专业分词支持:集成 pg_tokenizer.rs 多语言分词器,支持中文等专业分词
配置预览(提议中的设计):
|
|
现状:RFC 阶段,等待 maintainer 反馈。如果你也想要这个功能,可以去 Issue 点个 👍 表达支持。
合入后,我会第一时间写一篇"从 qmd 迁移到 PostgreSQL memory backend"的实战指南。
相关阅读
- 为什么我在 Agent 项目里只认 PostgreSQL:向量搜索篇 - 深入了解向量检索在 Agent 应用中的作用
- 向量数据库中的门门道道 - 向量搜索技术基础
本文基于 OpenClaw 生态现有方案整理,欢迎发现新项目后补充更新。