Postgres 高可用
最近在研究 Postgres 高可用的方案,这里记录一下。
Postgres 高可用
高可用目标
Postgres 高可用一般有两个目标:
- RPO(Recovery Point Objective)即数据恢复点目标,主要指的是业务系统所能容忍的数据丢失量。
- RTO(Recovery Time Objective)即恢复时间目标,主要指的是所能容忍的业务停止服务的最长时间,也就是从灾难发生到业务系统恢复服务功能所需要的最短时间周期。 简单来说就是,在多长时间内恢复数据库恢复到什么状态,比如在 5min 内恢复到丢失数据不超过 30min 的状态。当然最好的情况就是 RTO < 30s, RPO~=0。
场景
为了达到上面的这个最好的情况,需要覆盖以下场景:
- 当 Primary 节点发生故障时,自动切换到 Standby 并在 RTO 的要求下恢复到 RPO 目标。
- 当数据库发生数据的意外删除、升级变更错误、或者遇到硬件故障等,可以恢复到指定时间点。
概念
为了满足以上场景需要有以下技术或者概念的支持:
- Continuous Archiving:Continuous Archiving 一般是是对 WAL(writer ahead log) 进行归档;如果遇到 db system crash 可以通过 replay WAL 来进行恢复。
- Point-in-Time Recovery (PITR) :对于硬件故障来说,基于物理复制的高可用故障切换可能会是最佳选择。而对于数据损坏(无论是机器还是人为错误),时间点恢复(PITR)则更为合适:它提供了对最坏情况的兜底。
- Physical Replication:数据文件和事务日志文件全部复制 (PGData, pg_wals)
- Logical Replication:根据复制的标记(例如主键)在发布和订阅之间进行复制,一般不用于容灾,FDW 场景居多。
- Streaming Replication :基于 WAL 日志的流复制,主要用于容灾场景。将 WAL XLOG 记录连续从 primary 传送到 standby, 有同步以及异步两种方式。
工具
Backup and Restore
这里首先列举下常用的备份和恢复方式以及优劣:
1. Pg_dump (Logical Backup)
逻辑备份是通过 SQL 命令 pg_dump 将数据库中的数据导出到一个文件中,然后通过 SQL 命令将数据导入到数据库中。
优势:
- 根据需要,逻辑备份可以是表级到数据库级
- 备份不会阻止数据库上的读/写活动
- 可以恢复到 PostgresSQL 的不同主要版本,甚至不同的操作系统架构中 劣势:
- 逻辑备份在恢复时,需要 replay ,如果数据量大,需要很长时间,而且可能会降低整体性能
- 不支持全局变量的 dump, 只能用 pg_dumpall
2. Physical Backup
物理备份是停止 PostgreSQL 集群后进行的 PostgreSQL 离线备份,这些备份包含整个集群数据。 优势:
- 备份和恢复速度快
- 适合大型数据库
- 适合高可用场景 劣势:
- 不能跨版本恢复
- 不能跨操作系统恢复
3. Continuous Archiving and Point-in-Time Recovery (PITR)
Online Backup 或者叫 Hot Backup, 先进行完整的备份,可以在不停止 PostgreSQL 集群的情况下在线进行。增量备份生成的 WAL 日志,然后可以通过恢复 WAL 来恢复存档/WAL。 优势:
- 可以恢复到任何时间点
- 不会导致应用程序出现任何停机 劣势:
- 可能需要很长时间才能从存档中恢复数据,这些主要用于容量巨大、无法进行频繁备份的数据库。
4. Snapshots and Cloud Backups
快照需要操作系统或者 cloud provider 的支持,有rsync等工具可以用来拍摄快照。 劣势:
- 不适用于数据库将表空间存储在多个驱动器卷中的情况。
备份需要考虑很多情况,比如备份的频率、备份的存储位置、备份的恢复时间、备份保留策略等等,所以需要一些工具辅助我们来进行备份,下面列举一些常用的开源工具如下:
- pgbackrest
- EDB barman
- WAL-G 从这个讨论中,可以看到 barman 相对于 pgbackrest 还是有些功能的缺失:
- Zstd 压缩
- Delta restore
- Encryption at rest
- Native postgres page checksum validation
- Multi repo
High Availability
Patroni 默认使用的是异步的 Streaming Replication,这意味着主节点上的事务提交后,可能会有一段时间才会被复制到备节点上。这段时间内,如果主节点发生故障,可能会丢失这段时间内的数据。为了减少这种数据丢失,可以使用同步复制,但是同步复制会影响主节点的性能,因为主节点必须等待所有备节点都已经接收到并写入 WAL 日志后才能提交事务。所以需要在可用性和性能之间做平衡。
Patroni 的 maximum_lag_on_failover 和 pg 的 wal_segsize 的大小,需在可用性和持久性之间做平衡。
maximum_lag_on_failover默认 1MB(1048576 bytes) 意思是如果有个节点滞后超过这个值,就不会被选为新的主节点。一般配合loop_wait和ttl参数 一起使用。例如 ttl 是 30 的话,如果 Patroni 节点在 30 秒内未能与 Etcd 或 Consul 续约,则该节点将被认为失去了领导权。loop_wait 设置为 10 秒,Patroni 每隔 10 秒执行一次其主要操作循环,包括状态检查和必要的操作。最坏的情况下的丟失量:maximum_lag_on_failover 字节+最后的 TTL秒时间内写入的日志量。减小该值可以降低故障切换时的数据损失上限,但也会增加故障时因为从库不够健康(落后太久)而拒绝自动切换的概率。wal_segsize参数定义了每个 WAL 日志段文件的大小,默认是 16MB
架构
目前 Postgres 高可用架构繁多,这里列举两种常见的架构,分别对应自建 Postgres 以及云上托管 Postgres 的典型架构:
Pigsty HA 架构
下图来自于 pigsty:
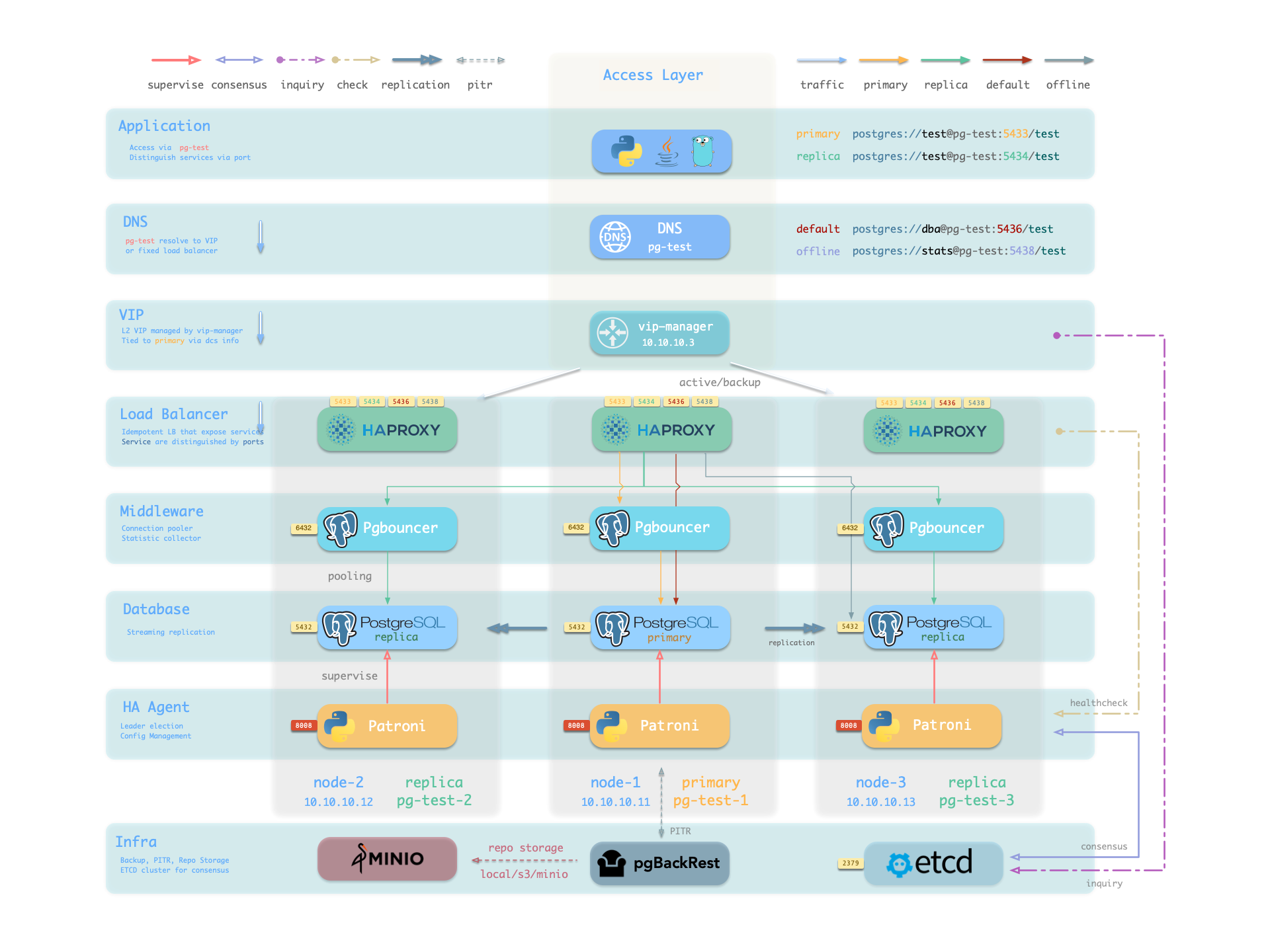
自上而下:
- 应用层通过 DNS 解析到 vip-manager 的 VIP,vip-manager 通过 etcd 获取当前主库的 IP 地址,然后将 L2 VIP 绑定到主库所在节点;通过 HAProxy 进行 L5 层端口转发。
- Patroni:同步主节点信息给到 etcd。
- vip-manager:虚拟 ip 和状态由 etcd 进行同步管理。
- HAProxy:根据端口分别进行路由
- 5433:连接 PGBouncer 连接池,连接 primary 进行 read/write
- 5434:连接 PGBouncer 连接池,连接 replica 进行 read-only
- 5436:直连 primary,管理使用
- 5438:直连 replica,管理使用,连接不处理在线读取流量的专用副本,用于ETL和分析查询。
- primary 和 replica 通过 Streaming Replication 进行 WAL 日志的同步,primary 通过 pg_receivexlog 将 WAL 日志发送到 replica,replica 通过 pg_replay 进行 WAL 日志的重放。
- Patroni 通过 pgBackRest 进行备份,备份数据可存储在本地,远程 s3 或者 minio 存储中, 可参考文档。
- PostgreSQL 使⽤标准流复制搭建物理从库,主库故障时由从库接管。
- Patroni 负责管理 PostgreSQL 服务器进程,处理高可用相关事宜。
- Etcd 提供分布式配置存储(DCS)能力,并用于故障后的领导者选举
- Patroni 依赖 Etcd 达成集群领导者共识,并对外提供健康检查接口。
- HAProxy 对外暴露集群服务,并利⽤ Patroni 健康检查接口,自动分发流量至健康节点。
- vip-manager 提供一个可选的二层 VIP,从 Etcd 中获取领导者信息,并将 VIP 绑定在集群主库所在节点上。 在主从架构+故障自动切换+同步 streaming replication +pgBackRest 备份的情况下 RTO 在 1min 内且 RPO 为 0,即在不丢失数据的情况下 1min 恢复。
Cloudnative-PG HA 架构
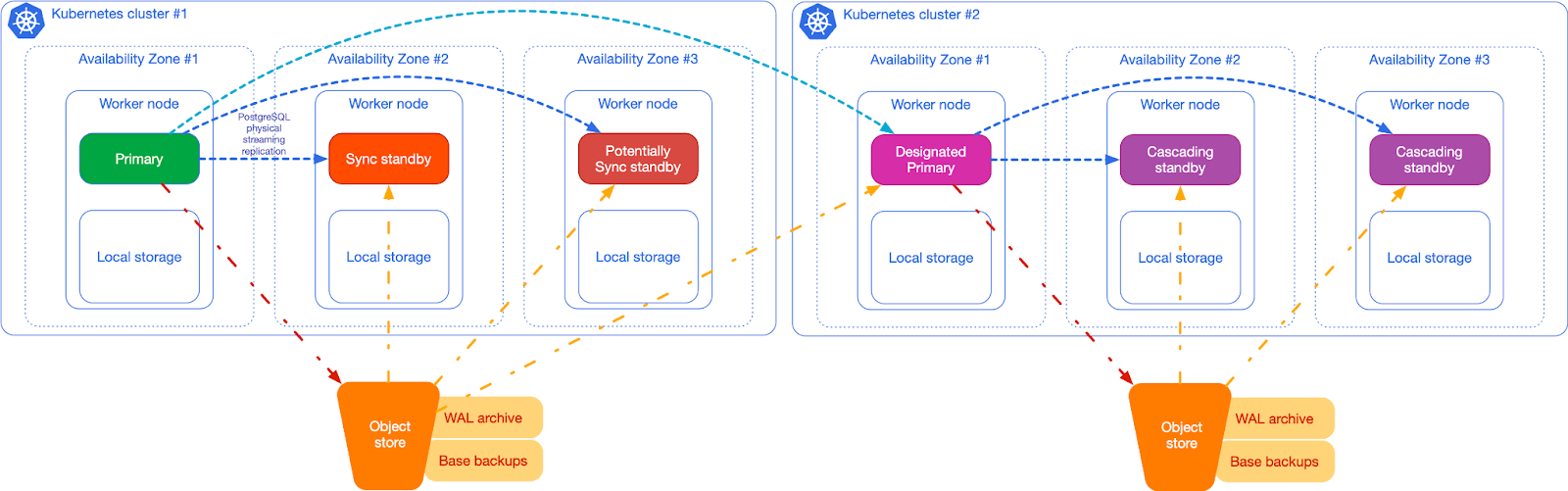
根据 Kubernetes 容器编排的特点,Cloudnative-PG HA 架构采用了更加现代化的架构:
- 多 region 部署 Kubernetes
- 多可用区(大于等于3)部署 PostgreSQL 节点
- Primary-Standby 采用同步或者异步 Streaming Replication
- PostgreSQL 实例不共享资源,独占节点资源,在不同的 Kubernetes 工作节点,使用本地卷
- 应用层提供
rw、ro、r三种服务,分别服务连接主节点、只读工作负载的热备用副本、任意只读工作负载、在发生故障转移时,它会自动更新服务以指向升级的服务,确保来自应用程序的流量无缝重定向。 - 提供 Pooler 对象,创建 PGBouncer 连接池,用于连接主节点和只读节点
- 通过 Replica Cluster 跨多个 Kubernetes 集群部署 PostgreSQL
- 通过将 PostgreSQL 备份数据存储在多个 location、region 并可能使用不同的提供商(灾难恢复)来减少全局恢复点目标 (RPO)
- 通过利用主 Kubernetes 集群之外的 PostgreSQL 复制来减少全局恢复时间目标 (RTO)(高可用性)
- 指定的主集群可以随时升级,使副本集群成为能够接受写连接的主集群。
- WAL 通过 s3 进行归档
- 通过 barman 进行备份,可以备份到云对象存储例如 s3 或者使用 Volume Snapshot 进行备份
在上述架构下可为跨区域灾难恢复提供最多大约 5 分钟的 RPO,如果使用同步 Streaming Replication 可以达到 0 RPO, 且具备极低的 RTO。
Supabase Backup
Click me
```mermaid
graph TD;
A(Supabase Backup)--->B(Pro);
B(Pro)--->E(Database Size 0-40GB);
B(Pro)--->F(Database Size 40GB+);
B(Pro)--->G(PITR);
B(Pro)--->H(Read Replica);
E(Database Size 0-40GB)--->I(Logical Backup);
F(Database Size 40GB+)--->J(Physical Backup);
G(PITR)--->J(Physical Backup);
H(Read Replica)--->J(Physical Backup);
A(Supabase Backup)--->C(Team);
C(Team)--->K(Database Size 0-40GB);
C(Team)--->L(Database Size 40GB+);
C(Team)--->M(PITR);
C(Team)--->N(Read Replica);
K(Database Size 0-40GB)--->I(Logical Backup);
L(Database Size 40GB+)--->J(Physical Backup);
M(PITR)--->J(Physical Backup);
N(Read Replica)--->J(Physical Backup);
A(Supabase Backup)--->D(Enterprise);
D(Enterprise)--->O(Database Size 0-40GB);
D(Enterprise)--->P(Database Size 40GB+);
D(Enterprise)--->Q(PITR);
D(Enterprise)--->R(Read Replica);
O(Database Size 0-40GB)--->J(Physical Backup);
P(Database Size 40GB+)--->J(Physical Backup);
Q(PITR)--->J(Physical Backup);
R(Read Replica)--->J(Physical Backup);
```

Click me
```mermaid
graph TD;
A(Supabase Backup)-->B(Pro);
A(Supabase Backup)-->C(Team);
A(Supabase Backup)-->D(Enterprise);
B(Pro)-->E(Daily Backup, Retain 7 days);
E-->H(pg_dumpall logical backup, when database size > 40GB will use physical backup);
C(Team)-->F(Daily Backup, Retain 2 weeks);
F-->H(pg_dumpall logical backup, when database size > 40GB will use physical backup);
D(Enterprise)-->G(Daily Backup, Retain 1 month);
D-->J(physical backup);
```

Click me
```mermaid
graph LR;
A(Supabase PITR)-->B(WAL-G, archiving Write Ahead Log files, default 2 min or certain file size threshold and physical backups);
B-->C(2 minutes RPO);
C-->D(show database restore available from and latest restore available at);
```

Click me
```mermaid
graph LR;
A(PGVecto.rs Cloud PITR)-->B(barman-cloud-wal-archive archiving Write Ahead Log files, default 5 min or certain file size threshold and barman-cloud-backup for physical backups);
B-->C(5 minutes RPO);
C-->D(show database restore available from and latest restore available at);
D-->E(delete cluster will delete all wal and physical backups);
```
